Het geheim van een goed AI model om vegetatie te herkennen
Voordat je een model gaat ontwikkelen is de belangrijkste vraag waarom je een AI model zou willen inzetten om vegetatie te herkennen. Deze vraag beantwoorden we in een andere blog: “Waarom een vegetatiemonitoring met AI uitvoeren”.
Beginnen bij het begin
Een analyse van een gebied begint bij een intake met de opdrachtgever. Het belangrijkste om te achterhalen is wat de doelstellingen zijn die de opdrachtgever wil bereiken met de analyse. Na het eerste gesprek kunnen we al goed inschatten hoeveel werk er nodig is.
De hoeveelheid werk voor ons hangt af van een aantal zaken:
- Het aantal soorten dat herkent dient te worden
- Hoe groot de kleinste soort is die herkent dient te worden
- De grootte van het gebied

Een bezoek aan het gebied
Ecologen en beheerders zijn erg kundig in het maken van plannen en het onderhouden van een gebied. De ervaring met het inzetten van remote sensing en het inschatten van de mogelijkheden is vaak nog onbekend terrein. Wij vinden het Good Practice om met de opdrachtgever de soorten in het veld op te zoeken. Enerzijds krijgen wij als opdrachtnemer een goed gevoel voor het gebied en anderzijds hebben we hiermee onze eerste annotaties te pakken. Annotaties zijn voorbeelden voor het model om het te leren wat er gezocht moet worden. Verderop in de blog leggen we dit nader uit.
Tijdens het bezoek kunnen we de opdrachtgever ook adviseren welke soorten geschikt zijn om te herkennen. Wanneer we merken dat één enkele soort een goede indicatorsoort is voor een reeks van doelsoorten, kunnen we werk en kosten besparen door alleen deze indicator te herkennen. Vanuit de techniek kunnen we hier goed over adviseren.
De opname
Voor de meeste soorten is een resolutie van 2cm goed genoeg om tot een herkenning van 90% te komen. Vaak is er bij de opdrachtgever geen noodzaak voor een betere prestatie. Bij handmatig uitgevoerd veldwerk wordt een lagere nauwkeurigheid al heel normaal gevonden.
De beelden van 2cm kunnen worden ingewonnen door een drone of een vliegtuig. We kiezen het middel dat voor het oppervlakte het goedkoopste is voor de opdrachtgever. Ook kan er een voorkeur zijn voor een specifieke methode in verband met verstoring (zoals overlast voor fauna).
We kiezen speciaal voor de resolutie van 2cm omdat er bij deze resolutie gekeken kan worden naar de vorm van de bladeren en de structuur van gegroepeerde steelachtige soorten. Remote sensing met behulp van satellieten bestaat al heel lang en wordt door verschillende bedrijven toegepast om soorten en structuren te herkennen. Maar, het kent ook limitaties. Zelfs met de nieuwste satellieten zoals Pleiades NEO en SuperView NEO is de hoogst haalbare resolutie 30cm. Ons blokje van 2x2cm pixel grootte past dus 225x (!) in het blokje van 30x30cm satellietbeelden. De resolutie die we toepassen is dus 225x scherper. Je kan je voorstellen dat dit een enorm verschil maakt in de mogelijkheden van de toepassingen.

 Deze luchtfotos hebben een GSD (Ground Sampling Distance) van 2cm. Meer over resolutie schreven we in deze blog onder het kopje 'Resolutie'.
Deze luchtfotos hebben een GSD (Ground Sampling Distance) van 2cm. Meer over resolutie schreven we in deze blog onder het kopje 'Resolutie'.
Satellietbeelden zijn zeker niet nutteloos bij natuurmonitoring en geschikt om grote aaneengesloten stukken van dezelfde vegetatie op te sporen zoals trends op het gebied van vergrassing of het detecteren van pijpenstrootjes in grote velden.
De hoge resolutie beelden geven inzicht in het voorkomen van een enkele struikheide, korstmossen, helmgras en eigenlijk elke soort die we tot nu toe voorgeschoteld hebben gekregen. Uiteraard kunnen bepaalde grootte en voldoende contrast met de omgeving wel beperkend zijn. Ook verhogen we de resolutie soms tot wel 0.3cm om zeldzame orchideeën of kleine watersoorten in beeld te brengen. Ter vergelijking: Dit is 10.000x scherper dan satellietbeelden.

Het veldwerk
Behalve dat het fantastisch is om de mooiste gebieden van Nederland te bezoeken, is alles automatiseren van achter een bureau simpelweg niet mogelijk. Om een model te trainen zijn voorbeelden van de te herkennen soorten nodig.
Medewerkers van Ecogoggle gebruiken tijdens veldwerk zelf ook het klantportaal floralyze.nl terwijl ze de doelsoorten aanmerken op de eerder gemaakte beelden.
Het primaire doel van een remote sensing-analyse is tijdsbesparing. Toch vereist het model training aan de hand van voorbeelden, die niet vanzelf komen. Daarom is veldwerk van essentieel belang. Ecogoggle is in staat om veldwerk zelfstandig uit te voeren, maar we geven er de voorkeur aan om samen te werken met ecologen van onze opdrachtgevers of met studenten en wetenschappers van instellingen zoals de WUR, HAS of Naturalis. Veldwerk is dus nog steeds essentieel, echter gebeurt dit nog maar in een klein gedeelte van het totale gebied, net genoeg om het model te trainen.
Het annoteren
De resultaten van het veldwerk worden op kantoor omgezet in nauwkeurige annotaties. Deze annotaties vormen de dataset waar het algoritme op gaat trainen, testen en valideren. In de machine learning wereld spreekt men altijd over “garbage in is garbage out”. Dit wil zeggen, als de brondata die je gebruikt om een model te trainen niet zuiver is, dat de uitkomsten ook nooit zuiver kunnen zijn. In de beelden worden planten aangemerkt als een specifieke soort of als achtergrond. Wanneer je per ongeluk een doelsoort niet aanmerkt als doelsoort wordt deze tot de achtergrond gerekend, hetgeen desastreuze gevolgen kan hebben voor het eindresultaat.
In de wetenschap is men het erover eens dat voor het classificeren van een model om plantensoorten te herkennen, segmentatiemodellen het beste presteren. Wij gebruiken dan ook uitsluitend dit type modellen. Helaas is het veel meer werk om segmentatiemodellen te maken dan object detection- of classification-modellen. Wij besteden per opdracht ongeveer 80% van onze tijd aan het maken van de dataset. Het ontwikkelen van een goed AI model is daarna gelukkig veel minder werk.
Vanuit de samenleving ontstaat steeds meer argwaan voor het gebruik van AI. De opdrachtgevers waarvoor wij werken vragen dan ook steeds vaker om metadata te leveren over de data die is gebruikt bij het trainen van de modellen. Deze metadata wordt gegenereerd vanaf de annotaties. Met het Ministerie van Binnenlandse Zaken hebben we het Impact Assessment Mensenrechten en Algoritmes (IAMA) traject doorlopen waaruit bleek dat de algoritmen die we ontwikkelen in de laagste risicocategorie vallen.
Itereren
Wanneer we een model hebben getraind kunnen we goed zien waar het model nog tekortschiet. We voorzien het model van extra annotaties van de soorten die nog ondermaats presteren. Ook gaan we het veld in om de prestaties te valideren. Te weinig data is vrijwel altijd de oorzaak van het probleem en dus blijven we meer data (voorbeelden) toevoegen tot wij en de opdrachtgever tevreden zijn. Het komt vaak voor dat we opnieuw het veld in gaan om meer planten van een bepaalde soort te zoeken.

Rapportage
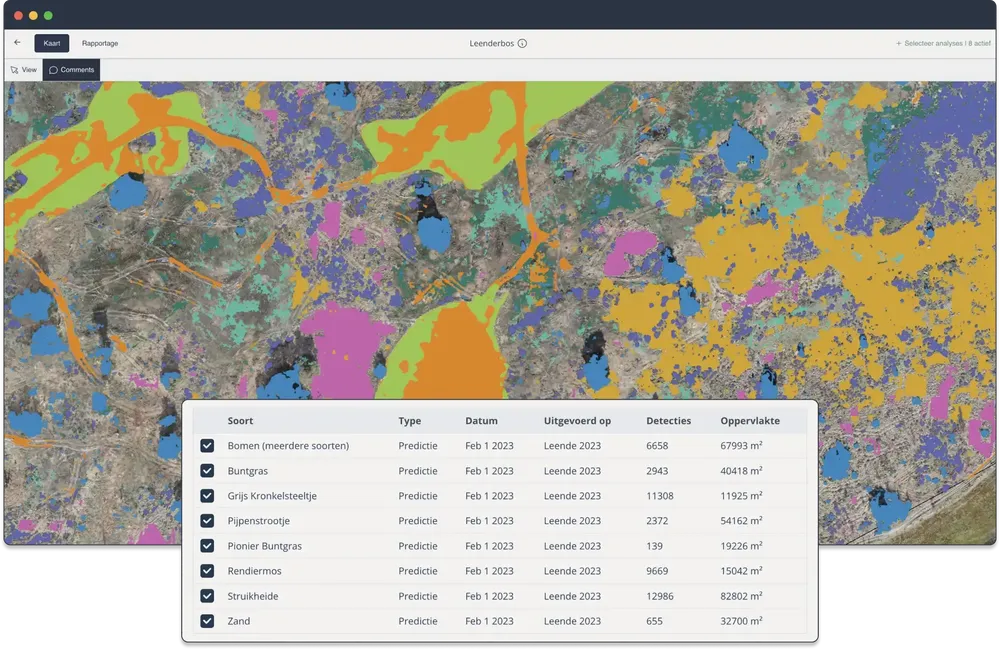
In het floralyze.nl portaal voor onze opdrachtgevers staan de opnames en alle analyses klaar om te bekijken. Het is voor veel opdrachtgevers fijn dat dit portaal er is zodat collega’s die niet goed overweg kunnen met GIS systemen toch makkelijk inzicht kunnen krijgen. De experts en de IV mensen van onze opdrachtgevers hebben altijd de voorkeur om analyses te bekijken in een portaal/systeem van de opdrachtgever zelf. Daarom zijn alle beelden en analyses uit ons portaal te downloaden of te koppelen met het eigen systeem via een API (Application Programming Interface).
Is het model nu klaar? Kunnen we het de volgende keer meteen weer inzetten?
Het slechte nieuws is dat het model eigenlijk nooit klaar is. Dit komt doordat planten enorm verschillen in uiterlijk door invloeden van neerslag, voeding, begrazing, de tijd van het jaar en allerlei andere invloeden. Ook zijn er vele verschillen per gebied. Niet alleen kan de doelsoort daar op een andere manier groeien maar ook de planten in de “achtergrond” klasse kunnen verschillen. Dit zou kunnen zorgen voor false positives, waarbij het model onbekende “achtergrondplanten" onterecht aanwijst als een doelsoort.
Gelukkig beginnen we voor dezelfde soorten nooit helemaal opnieuw. Het toevoegen van een paar extra voorbeelden in een nieuw gebied is vaak al genoeg. Een deel daarvan gebruiken we dan als training en een deel ter validatie. Je zou dit kunnen zien als een APK voor het model, een controle en wat klein onderhoud om alles weer soepel te laten verlopen. Het finetunen van de dataset en het model telkens herhalen maakt het model steeds robuuster. Des te vaker je het model tuned met een paar nieuwe voorbeelden des te nauwkeuriger werkt het.
Waarom vegetatie analyseren met een algoritme?
De vraag waarom onze opdrachtgevers vraagstukken bij ons uitzetten beantwoorden we in een andere blog “Waarom een vegetatiemonitoring met AI uitvoeren”.